Some time ago I had a fuzzy string matching problem to solve. I started looking for a performant Damerau-Levenshtein crate, and ended up writing my own collection of optimized edit distance algorithms, Eddie.
In this post, using the lessons I've learned along the way and the Levenshtein algorithm as an example, I'll build upon a basic implementation step by step, and measure the results.
Here are the takeaways:
- Reuse vectors to avoid allocations; use interior mutability pattern to keep the public interface nice.
- Copy string chars into a vector buffer if you need to iterate over it multiple times.
- Double down on iterators to avoid bounds checking in loop-heavy code, or get ready to get your hands dirty with unsafe code.
Levenshtein recap
If you are not familiar with the Levenshtein distance, check out its Wikipedia page, or google "levenshtein explained", or just keep reading: you will understand the optimizations well enough without a full grasp of the algorithm.
The definition of the distance is simple: it's the number of edit operations required to transform one string to another. There are three possible operations: insertion, deletion, and substitution of a single character.
For example, the distance between words "kitten" and "biting" is 4, because we need four operations to transform one word into the other:
- bitten (substitute k with b),
- biten (delete t),
- bitin (substitute e with i),
- biting (insert g).
The classic implementation uses dynamic programming technique, utilizing a distance matrix, where each cell contains Levenshtein distance between two substrings. Distances for longer substrings are computed using the results of shorter ones.
In pseudocode:
for i in 1 .. len1 + 1:
for j in 1 .. len2 + 1:
matrix[i, j] = min(
matrix[i - 1, j] + 1, # deletion
matrix[i, j - 1] + 1, # insertion
matrix[i - 1, j - 1] + int(str1[i] != str2[j]) # substitution
)
return matrix[len1 + 1, len2 + 1]Version 1: Basic Implementation
Translating the pseudocode above:
for (i1, ch1) in str1.chars().enumerate() {
for (i2, ch2) in str2.chars().enumerate() {
let i1 = i1 + 1;
let i2 = i2 + 1;
matrix[i1][i2] = min!(
matrix[i1][i2 - 1] + 1,
matrix[i1 - 1][i2] + 1,
matrix[i1 - 1][i2 - 1] + (ch1 != ch2) as usize
);
}
}
return matrix[len1][len2]Before we jump into the Rust stuff, this version needs to be fixed, especially the vec of vec's part. Storing 2D matrix this way, while intuitive, is awful performance-wise, for two reasons:
- Allocation is a relatively slow operation, and there are a lot of them.
- Reading or writing an item would require dereferencing two pointers (and two bound checks).
Storing a 2D matrix in a single vector is a common technique that is used instead. Implementation is quite simple:
use std::ops::Index;
pub struct Matrix<T> {
size: usize,
raw: Vec<T>,
}
impl<T> Index<(usize, usize)> for Matrix<T> {
type Output = T;
fn index(&self, (i, j): (usize, usize)) -> &Self::Output {
&self.raw[i * self.size + j]
}
}
// Add similar IndexMut implementation to be able to mutate the matrix.But we will skip this step alltogether, because we don't even need a matrix. Notice that each step requires only values not farther than i1-1 and i2-1, so the matrix can be replaced with a single row and a couple of additional variables to store previous results:
let row: &mut Vec<usize> = &mut (1 .. len2 + 1).collect();
for (i1, ch1) in str1.chars().enumerate() {
let mut dist_del = i1 + 1;
let mut dist_sub = i1;
for (i2, ch2) in str2.chars().enumerate() {
dist_del = min!(
row[i2] + 1,
dist_del + 1,
dist_sub + (ch1 != ch2) as usize
);
dist_sub = row[i2];
row[i2] = dist_del;
}
}This version of the algorithm is quite common, and this is what you can expect in your typical Levenshtein package in any language. This is our baseline, so let's measure it:
| Version | Time | Speedup |
|---|---|---|
| 1. Basic | 2.51 μs | - |
Now it's time for Rust-specific optimizations!
Version 2: Getting rid of allocations
Allocations are often a good issue to tackle first. In our case, we can avoid them if we create the row vector once and then reuse it beween function calls. There are basically two ways to do that: turn the function into a struct method, or use static thread_local buffers.
Things to consider:
- When using a struct you must carry an instance around, passing it from parent piece of code to its children, which is harder than just a simple import of a function.
- With an instance you carry all its resources, which can be freed when needed. It can be useful if you compare large texts that require large buffers. (This becomes much more relevant for the Damerau-Levenshtein algorithm, where you need a full distance matrix that can grow very fast.)
Performance-wise those ways are the same, so I'll just pick the one with a struct and stick with it. Implementation could look like this:
struct Levenshtein {
row: Vec<usize>,
}But this version would hold us back: the vector needs to be mutable, and we will be forced to use a mutable reference to the struct instance, which prevents sharing it freely within a thread.
Instead we will use RefCell and the "interior mutability" pattern, that allows mutating the data while retaining immutable references to it. Read about it in details in Rust Book.
pub struct Levenshtein {
row: RefCell<Vec<usize>>,
}
impl Levenshtein {
pub fn distance(&self, str1: &str, str2: &str) -> usize {
// ...
let row = &mut *self.row.borrow_mut();
store(row, 1 .. chars2.len() + 1);
// ...
}
}Implementation of the store function:
buffer.clear();
for val in iter {
buffer.push(val);
}Notice that .clear() doesn't affect vector's capacity, so recurring calls will not be slowed down by new allocations, unless you feed it larger and larger inputs.
Let's measure it:
| Version | Time | Speedup |
|---|---|---|
| 1. Basic implementation | 2.51 μs | - |
| 2. Reusable vectors | 1.42 μs | 43% |
Did you ever hear about the allocation bottleneck? Now you see how it goes: it's twice as fast, all thanks to just a single allocation. Let's see where else can we find some code to speed up.
Version 3: Replacing strings with vectors
Rust strings are encoded with UTF-8, which means that a single character can be stored in multiple bytes of an underlying slice:

The main performance implications are:
- Getting length is slow because you need to iterate through the string to get it;
s.len()isn't the right way to do it,s.chars().count()is. It's not ideal, but the problem of obtaining grapheme clusters ("visual letters") from a text in Unicode is a whole another dimension of fear and suffering, so we won't be doing that. - Iterating over characters is slow compared to vectors, because an iterator have to observe incoming bytes and figure out where one character ends and another begins.
Let's compare how fast we can iterate over string characters, compared to vector items:
| Version | Result |
|---|---|
for c in string.chars() { ... } |
21.3 ns |
for c in vector.iter() { ... } |
12.4 ns |
Turns out, string iteration is twice as slow. And we use it a lot, so maybe we should copy characters into a vector and then iterate over that vector instead.
We still need to iterate once to store the characters, but we were doing it anyway to calculate length. We only need to bufferize the second string, since the first one is iterated over just once:
impl Levenshtein {
pub fn new() -> Levenshtein {
Levenshtein {
row: RefCell::new(Vec::with_capacity(DEFAULT_CAPACITY)),
chars2: RefCell::new(Vec::with_capacity(DEFAULT_CAPACITY)),
}
}
pub fn distance(&self, str1: &str, str2: &str) -> usize {
// ...
store(chars2, str2.chars());
store(row, 1 .. chars2.len() + 1);
// ...
}
}And let's measure it:
| Version | Time | Speedup |
|---|---|---|
| 2. Reusable vectors | 1.42 μs | - |
| 3. Storing chars in vectors | 1.18 μs | 17% |
Version 4: Replacing index access with iterators
If you are not familliar with Vec internals, I would highly recommend to check out this post: Understanding Rust's Vec and its capacity for fast and efficient programs. It will come in handy in the next two sections.
Every index access in Rust has a cost of bounds checking: under the hood of each vec[i] is an assertion i < vec.len(). The common optimizing advice is to use iterators, but keep in mind that it may not be possible if you need to read or write to an arbitrary index.
Let's see if we can get rid of index access in our case, namely the three occurrences of row[i2] in the internal loop:
for (i2, &ch2) in chars2.iter().enumerate() {
dist_del = min!(
row[i2] + 1, // 1
dist_del + 1,
dist_sub + (ch1 != ch2) as usize
);
dist_sub = row[i2]; // 2
row[i2] = dist_del; // 3
}There are three ways one could go about it:
- Fall back to unsafe code and replace
row[i2]withrow.get_unchecked(i2)androw.get_unchecked_mut(i2). Sincerowis the same length aschars2, we can be sure thati2is always less thanrow.len(). - Alternatively, reduce the number of bound checks to one by storing the pointer to the item in a variable:
let item = row.get_mut(i2). - Finally, we can get rid of bounds checking altogether, while staying in safe code: iterate
chars2androwsimultaneously, using.zip(). (Yes you can use mutable and immutable iterators together.)
Using the third option:
for (&ch2, row_item) in chars2.iter().zip(row.iter_mut()) {
dist_del = min!(
*row_item + 1,
dist_del + 1,
dist_sub + (ch1 != ch2) as usize
);
dist_sub = *row_item;
*row_item = dist_del;
}This modification has saved us 15% of execution time:
| Version | Time | Speedup |
|---|---|---|
| 3. Storing chars in vectors | 1.18 μs | - |
| 4. No index access | 1.00 μs | 15% |
Version 5: Unsafe bufferization
In the previous section we addresed vec[i], and the operation we're interested in next is .push(). It sums up to a small part of our Levenshtein implementation, so we should expect a modest overal speedup after optimizing it. Still, for another code that writes into vectors a lot the technique below may be of great use.
Each .push() call has a cost of keeping the internal consistency:
- check if there is enough space to add new item;
- when not enough space, reallocate;
- when reallocated, update the pointer;
- update the length property afterwards.
If we had a vector as a source of items, we could reduce all that bookkeeping to a single .resize() call, and then use .zip() again:
ys.resize(xs.len(), default_value);
for (x, y) of xs.iter().zip(ys.iter_mut()) {
*y = *x;
}But the problem is that we have a string, and we can't know it's length beforehand. What we need is a function that grows the receiving vector dynamically as new items arrive.
To achieve that, let's code an example following the steps of the .push() implementation, except we'll be adding several items to a vector instead of just one. First, let's create a vector, reserve some additional capacity, and look at its layout:
let mut vec = vec![3, 14, 15];
vec.reserve(2);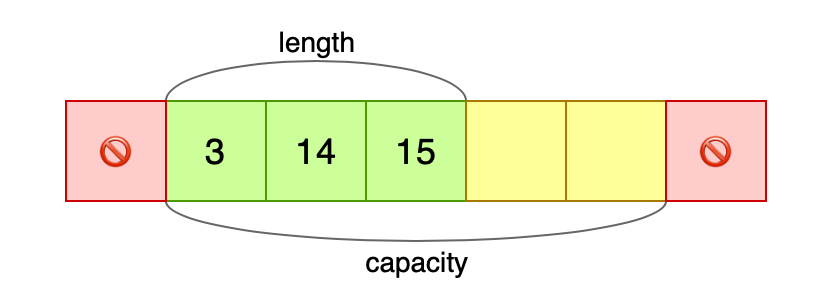
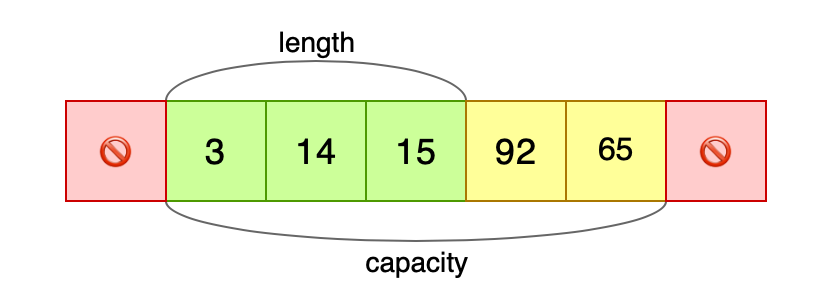
The green and yellow areas constitute all the memory allocated for the vector, and we can (un)safely write items to the yellow area, even though it is technically outside the vector:
let mut p = vec.as_mut_ptr();
unsafe {
std::ptr::write(p.offset(3), 92);
std::ptr::write(p.offset(4), 65);
}
All that's left is to set length manually:
unsafe {
vec.set_len(5);
}
dbg!(vec); // outputs [3, 14, 15, 92, 65]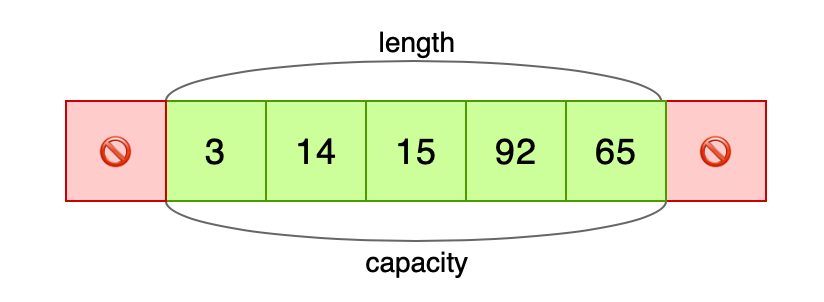
Let's return to the store function:
buffer.clear();
for val in iter {
buffer.push(val);
}And this is the new unsafe version:
buffer.clear();
let mut i = 0;
let mut p = buffer.as_mut_ptr();
for item in iter {
if i >= buffer.capacity() {
buffer.reserve(1);
p = buffer.as_mut_ptr();
}
unsafe {
ptr::write(p.add(i), item);
}
i += 1;
}
unsafe {
buffer.set_len(i);
}Let's measure the difference for the store function alone:
| Version | Time |
|---|---|
| Simple | 52.4 ns |
| Unsafe | 23.6 ns |
Twice as fast! Let's see how the unsafe version affects the overall performance of the Levenshtein implementation:
| Version | Time | Speedup |
|---|---|---|
| 4. No index access | 1.00 μs | - |
| 5. Unsafe bufferization | 0.95 μs | 5% |
Conclusion
Let's see the overall progress:
| Version | Time | Speedup |
|---|---|---|
| 1. Basic implementation | 2.51 μs | - |
| 2. Reusable vectors | 1.42 μs | 43% |
| 3. Storing chars in vectors | 1.18 μs | 17% |
| 4. No index access | 1.00 μs | 15% |
| 5. Unsafe bufferization | 0.95 μs | 5% |
In the end we achieved a moderate improvement, however the code was not so bad at the beginning. The same measures resulted in more than 4x speedup in the Eddie's Damerau-Levenshtein implementation. I've only picked Levenshtein for the demo since it's simple and widely accepted, but still allows to show all the good stuff.
The effectiveness of each technique depends not only on the algorithm, but also on the size of the data. For all measurements above I used English words of typical length (5-7 chars). If I were to use large texts, an impact of one-time vector allocations would be negligible compared to the amount of time spent in the loops.
There are some more little tricks in Eddie's implementation that were added after looking into another implementations in Rust and other languages, but this is a story for another post.
You can check out the code and run the benchmarks yourself, it's all in this repo.